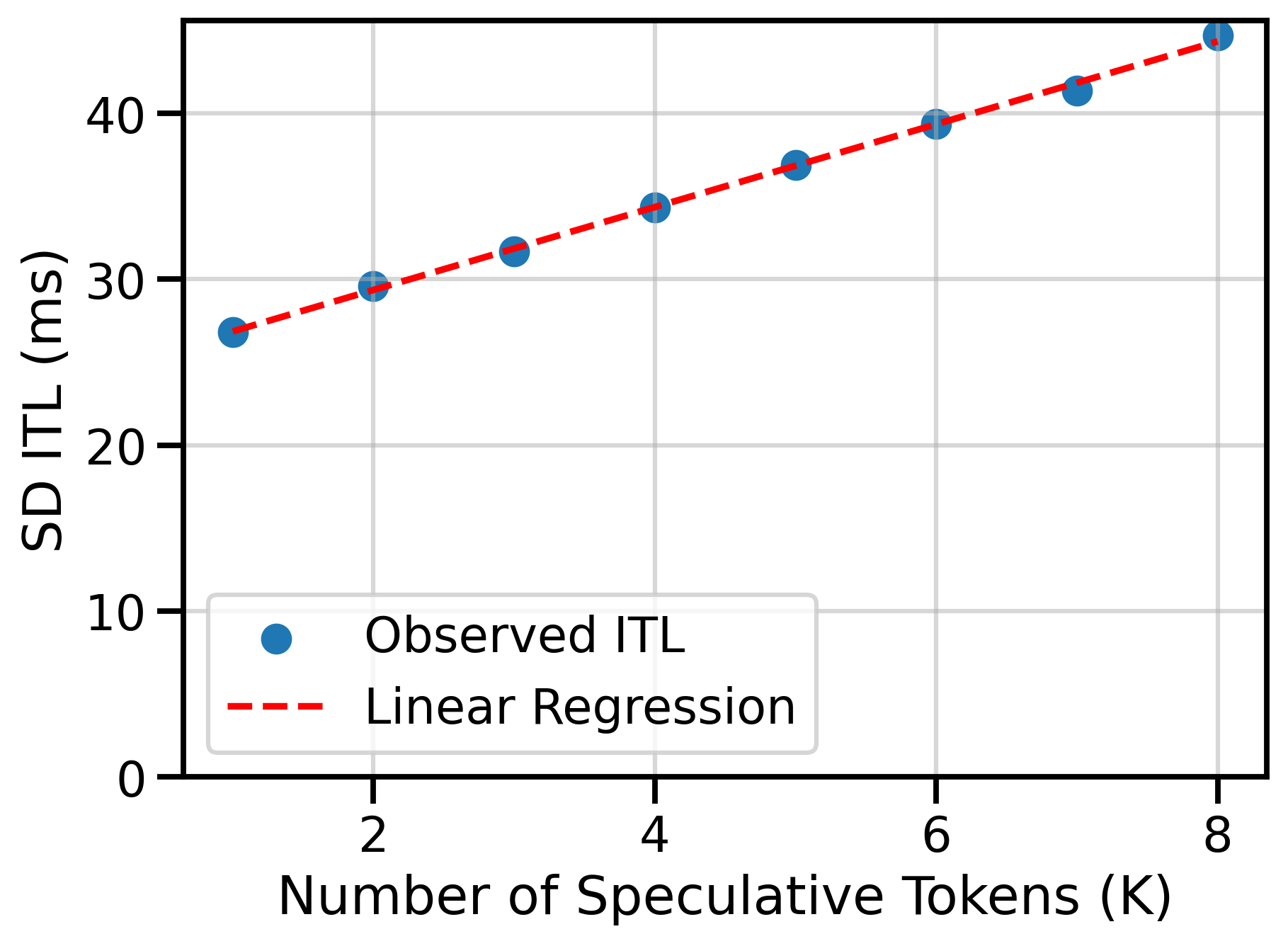
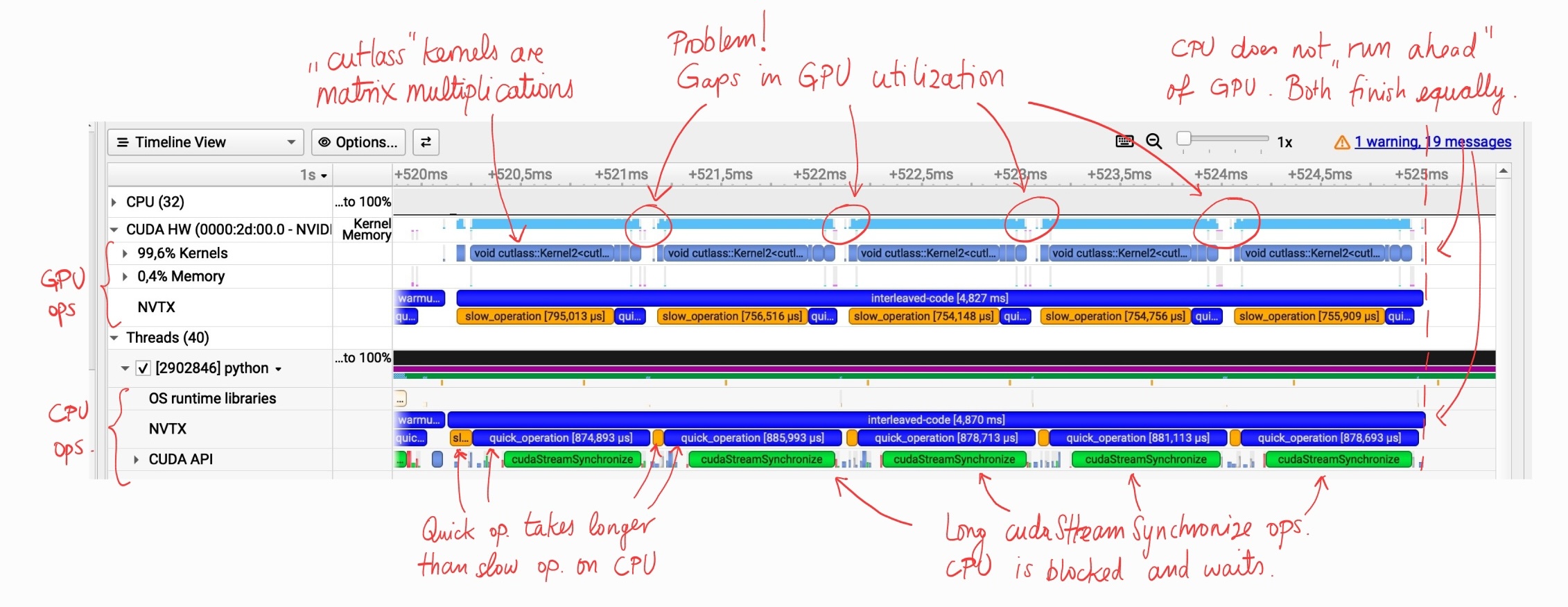
Forecasting the Performance of Full CUDA Graphs for Speculative Decoding
vLLM
CUDA
Performance
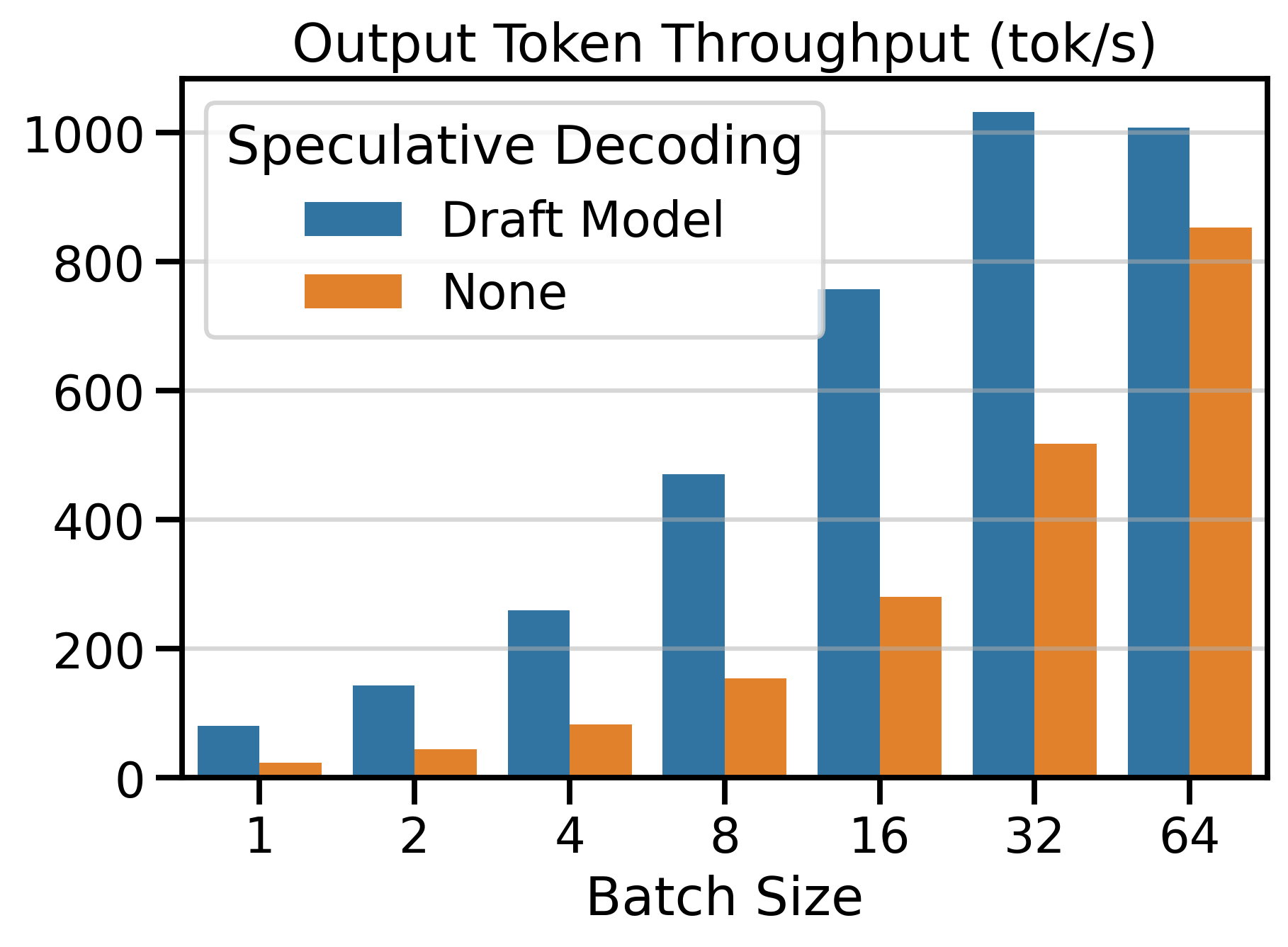
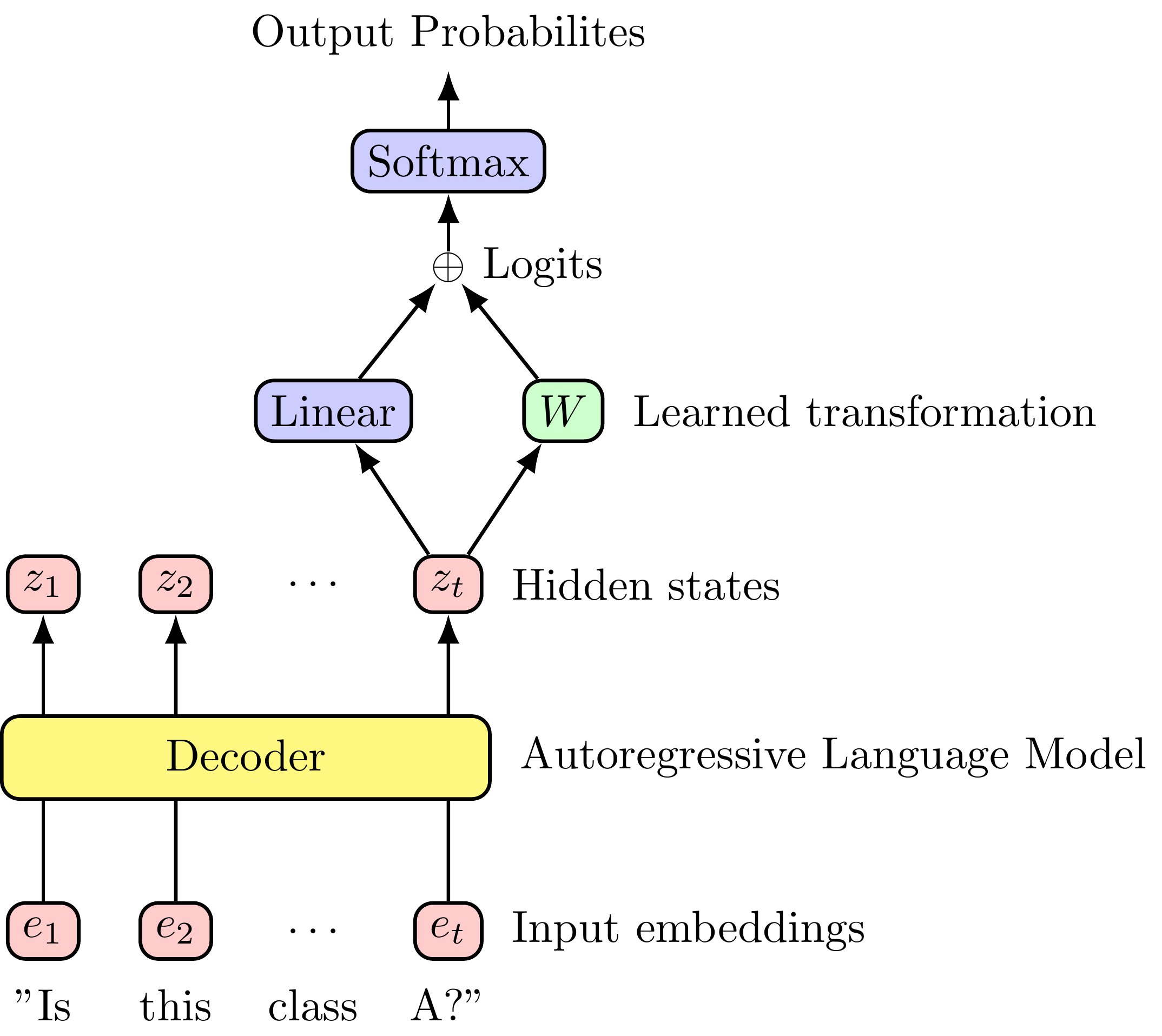
Up to 3.55x Faster: Contributing Speculative Decoding with Draft Models to vLLM V1
vLLM
PyTorch
Triton
Transformers

No matching items